A C++ Programmer's Guide to Rust
This is my reading note of The Book of Rust. To learn Rust it’s best to compare it with one language that I am experienced with. For me it’s C++. Following are some key differences between Rust and C++, organized the same as the book’s chapter.
- 3. Common Programming Concepts
- 4. Understanding Ownership
- 5. Using Structs to Structure Related Data
- 6. Enums and Pattern Matching
- 7. Managing Growing Projects with Packages, Crates, and Modules
- 8. Common Collections
- 9. Error Handling
- 10. Generic Types, Traits, and Lifetimes
- 11. Writing Automated Tests
- 13. Functional Language Features: Iterators and Closures
- 14. More About Cargo and Crates.io
- 15. Smart Pointers
- 15.1 Using
Box<T>to Point to Data on the Heap - 15.2 Treating Smart Pointers Like Regular References with the
DerefTrait - 15.3 Running Code on Cleanup with the
DropTrait - 15.4
[Rc<T>, the Reference Counted Smart Pointer](https://doc.rust-lang.org/book/ch15-04-rc.html#rct-the-reference-counted-smart-pointer) - 15.5
[RefCell<T>and the Interior Mutability Pattern](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#refcellt-and-the-interior-mutability-pattern)
- 15.1 Using
- 16. Fearless Concurrency
- 17. Object-Oriented Programming Features of Rust
- 19. Advanced Features
3. Common Programming Concepts
3.1 Variables and Mutability
- By default, all variables are immutable, which means that once they are initialized, they can not be changed
- Mutable variables must be explicitly declared:
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}
constand immutable differences:constvariable must be initialized at compile time, not at runtime- This is different from C++, in which const variables can be initialized at runtime
- Shadowing:
- We can declare the same named variable again using
letkeyword, this variable will replace previous declaration, this is called shadowing - Shadowing is not the same as variable reassignment:
- Reassignment does not change the type of the variable, only change the value
- Shadowing can change the type of the variable, after shadowing, they are two different variables
- We can declare the same named variable again using
fn main() {
let mut x = 5;
println!("Initial value of x is: {x}");
x = 6;
println!("Value after reassignment is: {x}");
// shadowing can chage the type
let x: char = 'h';
println!("Value after shadowing, with char type is: {x}");
{
// shadowing in inner scope
let x: char = 'c';
println!("The value of x in the inner scope is: {x}");
}
// inner scope shadowing does not influence outer scope
println!("The value of x is: {x}");
}
3.2 Data Types
Most of the types are very similar with C/C++, following are some key differences:
- Rust has integer type
isizeandusize, which is architecture dependent, for example 32 bits and 64bits system - Numbers can be concatenated using
_, such as23_12 - Tuple type can contain different types and can be accessed using dot attribute
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
- Array type has bounds check at runtime, in C++ this is undefined behavior
3.3 Functions
- Rust functions do not require first declaration, then use like C++, only require that function names can be accessed in the same name scope
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}
- statement and expression
- statement: do not return a value, ends with comma
; - expression: return a value, do not ends with comma
;- A new scope block created with curly brackets is an expression:
- statement: do not return a value, ends with comma
fn main() {
let y = {
let x = 3;
x + 1 // do not ends with ;
};
println!("The value of y is: {y}"); // 4
}
- Most functions return the last expression implicitly
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}
3.5 Control Flow
- Rust do not do implicit conversion to bool type like in C++; Conditions in Rust must be explicitly bool type
ifexpression:
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}
- Because
ifis expression, it returns value, it can be used on the right side to assign some value to variables; Note: every condtion must return the same type
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("The value of number is: {number}");
}
loopexpression:- Return value after
break looplabel to break any labeled loop
- Return value after
fn main() {
let mut count = 0;
'counting_up: loop { // here is counting_up label, starts with '
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up; // here from inner loop breaks outer loop
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {result}");
}
fn main() {
loop {
println!("again!");
break; // used to exit loop
continue; // used to skip one loop
}
}
whileexpression
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}
forexpression
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}
4. Understanding Ownership
4.1 What Is Ownership?
Compared with C++:
- Every variable have one and only owner, when the owner goes out of scope, the variable is dropped (desctructed in C++)
- Owner can be transfered, it’s like move semantics in C++(but not the same)
- By default, assignment, function parameter passing, function return are all action of tranfer of owner
- It can be over simply summarized as:
- By default, C++ use copy for assignment, function parameter passing and function return, except to specifically using rvalue reference
- By default, Rust use move for assignment, function paramete passing and function return, except to specifically implementing copy in the variable. Scalar types like integers, floats, chars are copied
- The Rust compiler will check the owner of every variable, when it goes out of scope, the variable is dropped
Ownership in Rust is NOT the same with move in C++:
- When variables are moved in C++, the variable is in valid but unspecified state. Destructor will still be called when the variable goes out of scope. Programmer need to take care of this.
- move will not change scope of a variable
- When ownership of variable in Rust is taken, the scope of the variable is changed, which means the time for calling the drop method is changed
- Even on the stack the ownership is important since it decides when the variable is dropped
- If the variable is totally on stack, even it’s memory is still valid, it can not be used, since the drop method might change it’s value
Both C++ and Rust can destruct variables on heap or stack:
- heap memroies are returned to OS
- stack memories might be still valid, but the value might be changed. So it still matters when to destruct the variable and what can be done on this stack memory
struct MyStruct {
_a: usize,
_b: usize,
}
impl Drop for MyStruct {
fn drop(&mut self) {
println!("droped, _a = {}", self._a)
}
}
fn main() {
let a = MyStruct { _a: 10, _b: 20 };
// add some variables on stack
let _s = 32;
let _t = 2.13;
{
// _b take ownership of _a
let mut _b = a;
_b._a = 20;
} // call drop
println!("end of main program");
// there will no more calling of drop anymore
}
// output:
// droped, _a = 20
// end of main program
#include <iostream>
#include <memory>
struct MyStruct {
int a = 10;
int b = 20;
~MyStruct() { std::cout << "dtor: " << a << ";" << b << std::endl; }
MyStruct(MyStruct &&other) {
a = other.a;
b = other.b;
other.a = 30;
other.b = 30;
std::cout << "being moved: " << other.a << ";" << other.b << std::endl;
}
MyStruct() = default;
};
int main() {
MyStruct m;
/// some other variables on the stack
int c = 200;
double d = 2.3;
// even though m is moved, it's destructor will still be called when
// m goes out of scope
MyStruct i = std::move(m);
}
// output:
// being moved: 30;30 # first being moved
// dtor : 10;20 # destructor of i
// dtor : 30;30 # destructor of m
4.2 References and Borrowing
Compared with C++:
- By default, a reference in C++ is mutable, user can use it to change the value it points to, except that explicitly specify that it is const referenceI
- By default, a reference in Rust is immutable, user can not use it to change the value it points to, except explicitly specify that it is a mut reference
- In C++, there is no reference to reference, but have rvalue reference; In Rust, there is no rvalue reference, but one can refer to reference like
&&&&a, which is parsed in following rule:- It will deref as many times as possible (
&&String->&String->String->str) and then reference at max once (str->&str).
- It will deref as many times as possible (
To avoid data race, Rust compiler assure:
- One and only one mutable reference is pointed to one variable, or
- Multi immutable reference are pointed to one variable
4.3 The Slice Type
- slice is used to reference to a contiguous sequence of elements in a collection rather than the whole collection
fn main() {
let strin: String = String::from("Hello World");
// string slice
let slic: &str = &strin[0..2];
println!("{}", slic);
let arr: Vec<i32> = vec![1, 2, 3, 4];
// vector slice
let arr_slic: &[i32] = &arr[1..3];
println!("{},{}", arr_slic[0], arr_slic.len());
}
- It’s better to use slice instead of the original collection type as function parameters, since slice type can accept both slice and original collection type. When original collection type is passed, it is coerced to slice type, it is called deref coercions
fn main() {
let strin: String = String::from("Hello World");
// string slice
let slic: &str = &strin[0..2];
println!("{}", slic);
let arr: Vec<i32> = vec![1, 2, 3, 4];
// vector slice
let arr_slic: &[i32] = &arr[1..3];
println!("{},{}", arr_slic[0], arr_slic.len());
// p_slice can accept both &String type and &str type
// Note that &strin is reference to strin
p_slice(&strin);
p_slice(slic);
p_str(&strin);
// following code do not compile
// p_str(slic);
}
fn p_slice(data: &str) {
println!("{}", data);
}
fn p_str(data: &String) {
println!("{}", data);
}
5. Using Structs to Structure Related Data
Compared with C++, except for difference in code format, the idea is basically the same for data encapulation.
5.2 An Example Program Using Structs
- Debug printing, add attribute to struct
#[derive(Debug)]
struct Rectangle{
width:u32,
height:u32,
}
fn main() {
let scale = 2;
let rect=Rectangle{
width:dbg!(scale * 30),
height:50,
};
let w=rect.width;
let h=rect.height;
println!("Rectangle is {:#?}, {}, {}", rect, w, h);
}
5.3 Method Syntax
Compared with C++, Rust does object orinented programming using impl keyword to implement method of object:
#[derive(Debug)]
struct Rectangle{
width:u32,
height:u32,
}
impl Rectangle{
fn area(&self)->u32{
self.width * self.height
}
}
fn main() {
let scale = 2;
let rect=Rectangle{
width:dbg!(scale * 30),
height:50,
};
println!("Area of Rectangle is {}", rect.area());
}
&selfis equivalent toself: &SelfwhereSelfis an alias for the type that theimplblock is for.- Methods can take ownership of
self, borrowselfimmutably, as we’ve done here, or borrowselfmutably, just as they can any other parameter. - All functions defined within an
implblock are called associated functions because they’re associated with the type named after theimpl.- If
selfas first parameter, this function is called method - Otherwise, it is not method, just associate functions, it can normally be used to:
- Constructors that are used to return a new instance of the struct
- If
#[derive(Debug)]
struct Rectangle{
width:u32,
height:u32,
}
impl Rectangle{
// This is method
fn area(&self)->u32{
self.width * self.height
}
// This is not method
fn new(size:u32)->Self{
Self{
width:size,
height:size,
}
}
}
fn main() {
let scale = 2;
let rect=Rectangle{
width:dbg!(scale * 30),
height:50,
};
println!("Area of Rectangle is {}", rect.area());
let rec=Rectangle::new(20);
println!("Area of Rectangle is {}", rec.area());
}
6. Enums and Pattern Matching
6.1 Defining an Enum
Compared with C++, Rust in enum is more powerfull:
- Every enum item can have associate values
- One or more associate values for each enum item and they can be different types
- Methods can be defined for enums like struct
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// method body would be defined here
}
}
let m = Message::Write(String::from("hello"));
m.call();
Option<T> is essential for Rust language, which is an enum that stores None if value not exist and Some<T> if value exist:
enum Option<T> {
None,
Some(T),
}
- The
Option<T>enum is so useful that it’s even included in the prelude; you don’t need to bring it into scope explicitly. - Its variants are also included in the prelude: you can use
SomeandNonedirectly without theOption::prefix. - Why it is better than just a
nullin C++: - In short, because
Option<T>andT(whereTcan be any type) are different types, the compiler won’t let us use anOption<T>value as if it were definitely a valid value. So every timeOption<T>is used, compiler requires programmer explicitly check the existence of the potentially stored value
6.2 The match Control Flow Construct
- When binding values in
enum, it depends on the matched instance whether the binding is reference or move- If the matched instance is reference, the bind is reference
- If the matched instance is not reference, the bind is move
#[derive(Debug)]
enum Fruit {
Apple,
Orange,
Grape,
Watermelom(String),
}
fn have_fruit(f: &Option<Fruit>) -> Option<Fruit> {
// No matter what return a Apple
match f {
None => Some(Fruit::Apple),
Some(fruit) => Some(Fruit::Apple),
}
}
fn main() {
let f: Option<Fruit> = Option::Some(Fruit::Grape);
dbg!(have_fruit(&f));
}
#[derive(Debug)]
enum Fruit {
Apple,
Orange,
Grape,
Watermelom(String),
}
fn define_fruit(f: &Fruit) -> u8 {
match f {
Fruit::Apple => 1,
Fruit::Orange => 2,
// value of Watermelom is bind to str, by reference, since f is reference
Fruit::Watermelom(str) => {
println!("qinline is watermelon, {}!", str);
4
} // , is optional
// _ matchs anything else; _=>() means do nothing
_ => {
println!("not important");
0
}
}
}
fn main() {
let qinlin = Fruit::Watermelom(String::from("Sweet!"));
define_fruit(&qinlin);
println!("{:#?}", qinlin);
dbg!(qinlin);
// since dbg!() takes ownership of qinlin, following line will be an error
// dbg!(qinlin);
}
6.3 Concise Control Flow with if let
if let is more concise version of match if we only care about one item and want to neglect the other options:
enum Fruit {
Apple,
Orange,
Pear(String),
}
fn main() {
let favorite: Fruit = Fruit::Pear(String::from("Delicious"));
// Here we use ref key word to specify bind by reference, otherwise
// it will bind by move, since favorite variable is not reference
match favorite {
Fruit::Pear(ref var) => println!("Pear is {}", var),
_ => println!("It is not pear"),
}
// if let version for same functionality above
// Note that here we do not use ref, it is bind by move
if let Fruit::Pear(var) = favorite {
println!("Pear is {}", var);
} else {
println!("It's not pear")
}
}
7. Managing Growing Projects with Packages, Crates, and Modules
Following are concept comparisons with C++:
- crates: The smallest amount of code that the rust compiler considers at a time
- This is NOT like C++, in C++, the smallest amount of code that compiler considers is one translation unit, aka, a single source file
- create can be compared to library or executable in C++, which might be compiled from multi cpp source files
- Rust do not use include to manage individual files, it requires files organized according to module and must be put under specific locations, while in C++ one can put file in anywhere as long as specify include path during compile time
- There are two kinds of crate: library crate and binary crate
- binary crate has main function while library crate not
- The crate root is a source file that the Rust compiler starts from
- packages:
- A package is a bundle of one or more crates that provides a set of functionality
- A package can contain as many binary crates as you like, but at most only one library crate. By default:
- src/main.rs is the crate root of a binary crate with the same name as the package
- Package contains a library crate with the same name as the package, and src/lib.rs is its crate root
- Use cargo new command to create a package
- module:
- module can be compared with namespace in C++, except that:
- module in Rust determine where Rust compiler find the file that contains the module
- Note that the
modkeyword declare module name, module tree is constructed through themodkeywords, while theusekeyword bring module name into current crate name space - For modules declared inside current crate, it’s absolute path starts with
crate:: - For external modules, it’s absolute path starts with it’s package name
- module can be compared with namespace in C++, except that:
Exmaple, for following file structure:
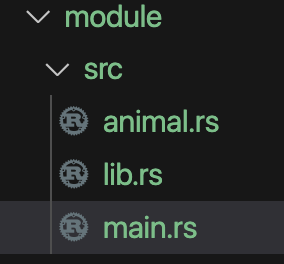
File module/src/animal.rs
pub struct Dog{
pub name:String
}
File module/src/lib.rs
// declaration, compiler search animal.rs
pub mod animal;
pub fn f(){
let d=animal::Dog{
name:String::from("nihao")
};
println!("{}", d.name)
}
File module/src/main.rs
// declaration, compiler search animal.rs
pub mod animal;
// the name `animal` is defined multiple times
// use module::animal;
// ok
// use module::animal as another_animal;
use module::f;
fn main() {
// modules inside the same crate, moudle starts with 'crate'
let d = crate::animal::Dog {
name: String::from("husky"),
};
// modules in external create, module starts with the package name
// here the package name is 'module'
// note that even though crate::animal::Dog and module::animal::Dog
// points to the same Dog in animal.rs, they are considered
// different Dogs inside current crate
let another_dog = module::animal::Dog {
name: String::from("teddy"),
};
f();
println!("{},{}", d.name, another_dog.name);
}
8. Common Collections
8.1 Storing Lists of Values with Vectors
Rust’s vector is very similar with that of C++, in following aspects:
- They both use type parameter, in C++ it’s template, in Rust it’s generic
- Their APIs are very similar, both support indexing with
[]or method
The key differences are:
- When use
[]operator, if happens out of bound access, Rust will crash - Whne use
get()API to access element, Rust reutrnOption<&T>, so user can usematchto handle the result
fn main() {
let arr: Vec<u8> = Vec::new();
let v = vec![1, 2, 3];
// This will cause runtime crash
// let r = v[100];
// This will not cause runtime crash
let m = v.get(100);
// Here we can use var or &var,
if let Some(var) = m {
println!("var is {}", var);
} else {
println!("index out of bound");
}
}
- Vec in Rust also obey ownership rule:
- At any time there can be multi immutable reference to any element, or
- At any time there can be only one mutable reference to only one of the elements
fn main() {
let mut v = vec![1, 2, 3, 4];
// Following lines are the same, i and j are both reference to i32
let _i = &v[0];
let &_j = &v[2];
v.push(3);
// Here panic because during the lifetime of bowrrow, mutable reference happens
println!("_i is {}", _i);
}
- Iteration is similar with C++
fn main() {
let mut v = vec![1, 2, 3, 4];
for i in &v {
println!("{}", i);
}
for i in &mut v {
//Note the dereference *
*i += 10;
println!("{}", i);
}
}
- Because of Rust have more powerful enum, which has a associate type for each item, vector in Rust can used to store different types indirectly with the help of enum:
enum DiffTypes {
Type1(i8),
Type2(i16),
Type3(String),
}
fn main() {
let v = vec![
DiffTypes::Type1(4),
DiffTypes::Type2(12345),
DiffTypes::Type3(String::from("Hello World!")),
];
for i in &v {
match i {
DiffTypes::Type1(var) => println!("{}", var),
DiffTypes::Type2(var) => println!("{}", var),
DiffTypes::Type3(var) => println!("{}", var),
}
}
}
8.2 Storing UTF-8 Encoded Text with Strings
- In Rust, string can refer to &str string slice type, which is built in type at the core of the language, or it can refer to String type which is a type implemented in std library and is implemented as vector of bytes
- Concatenate strings:
fn main() {
let mut h = "hello".to_string();
// sigature of push_str: push_str(&mut self, string: &str)
h.push_str("world");
println!("{}", h);
// signature of push: push(&mut self, ch: char)
h.push('!');
println!("{}", h);
let s1 = String::from("Hello");
let s2 = String::from("World");
// + operator take ownership of the first operand: fn add(self, s: &str) -> String {
let s3 = s1 + "nihao";
// do not compile since s1 has been moved in + operation
// println!("{}", s1);
println!("{}", s3);
let s1 = String::from("universe");
// use format!() macro to not take ownership to concatenate strings
let s4 = format!("{s1}_{s2}_{s3}");
println!("{}", s4);
// s1 still available
println!("{}", s1);
}
- string can not be indexed using
[]in Rust, such ass1[0], but can be sliced likes1[0..1] - Two kinds of iteration:
- Iterate over char:
for c in "Зд".chars() - Iterate over bytes:
for b in "Зд".bytes() - Note that Rust might store one char in different amount of bytes
- Iterate over char:
8.3 Storing Keys with Associated Values in Hash Maps
- Create, access and iterate HashMap
inserttake ownership of it’s parametersgettakes reference and return *Option*
use std::collections::HashMap;
fn main() {
let mut hp: HashMap<String, i32> = HashMap::new();
let s=String::from("Moved");
// Note insert takes ownership of the parameter
hp.insert("Tom".to_string(), 10);
hp.insert("Jerry".to_string(), 20);
// get takes any borrowed form of the map's key type and returns Option<&V>
// copied() method of Option turns Option<&V> to Option<V>
// unwrap_or function of Option return value if None
let a = hp.get("Harray").copied().unwrap_or(100);
println!("{}", a);
// iterate over has map, note the & sign, this means we use reference to print the value, without this sign, key and value will be moved
for (key, value) in &hp {
println!("{}:{}", key, value);
}
}
- Update key value:
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
// entry method: Gets the given key's corresponding entry in the map for in-place manipulation.
// or_insert method: Ensures a value is in the entry by inserting the default if empty, and returns a mutable reference to the value in the entry
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{:?}", scores);
}
9. Error Handling
There are two kinds of errors in Rust:
- recoverable:
Result<T, E> - unrecoverable:
panic
9.1 Unrecoverable Errors with panic!
Compared with C++, panic in Rust is crash, but Rust provide more user friendly debug infomation instead of just abort in C++, set the RUST_BACKTRACE=1 environment variable to print the crash backtrace.
9.2 Recoverable Errors with Result
Compared with C++’s try..throw..catch , Rust use one special enum to handle exceptions, Result<T,E>
enum Result<T, E> {
Ok(T), // T is the return value if no exception
Err(E), // E is error type if exception happens
}
One can process error in following ways:
match:
use std::fs::File;
fn main() {
let _file = match _file_result {
Ok(file) => file,
Err(_) => {
panic!("file open failed");
}
};
}
if let:
use std::fs::File;
fn main() {
let _file_result = File::open("hello.txt");
if let Ok(_file) = _file_result {
println!("file successfully opend");
} else {
panic!("file open failed");
}
}
unwrap- Return the result or panic
use std::fs::File;
fn main() {
let _file = File::open("hello.txt").unwrap();
}
expect- Same with
unwrapbut allow to specify custom message when panic
- Same with
use std::fs::File;
fn main() {
let _file_result = File::open("hello.txt").expect("file open failed");
}
Rust propagates errors by return a Result instance:
use std::fs::File;
use std::io;
use std::io::Read;
fn return_file(file_name: &str) -> Result<String, io::Error> {
//open file
let file_result: Result<File, io::Error> = File::open(file_name);
let mut file_d: File = match file_result {
Ok(file) => file,
// here have to use return , if not it returns to file_d, like file above
Err(error) => return Err(error),
};
let mut name: String = String::new();
match file_d.read_to_string(&mut name) {
// following line do not need return, it's last expression, returned by default
Ok(_) => Ok(name),
Err(error) => Err(error),
}
}
fn main() {
let _name: String = return_file("/home/swq/playground/rust_book/result/src/hello.txt").unwrap();
println!("{}", _name);
}
return_filereturnsResultobject, propagate possible errors at the same time
? operator:
use std::fs::File;
use std::io;
use std::io::Read;
fn return_file(file_name: &str) -> Result<String, io::Error> {
//The ? operator has two function:
// 1. unwrap and get the value in Result
// 2. if error, return the error from this function call
let mut file: File = File::open(file_name)?;
let mut name: String = String::new();
file.read_to_string(&mut name)?;
Ok(name)
}
fn main() {
let _name: String = return_file("/home/swq/playground/rust_book/result/src/hello.txt").unwrap();
println!("{}", _name);
}
? operator has two meaning:
- If get the value, return the value and go on with the function
- If get error in Result, return from this function and propagate this error to the caller
We can chain the operation without creating intermediate variables:
use std::fs::File;
use std::io;
use std::io::Read;
fn return_file(file_name: &str) -> Result<String, io::Error> {
let mut name: String = String::new();
File::open(file_name)?.read_to_string(&mut name)?;
Ok(name)
}
fn main() {
let _name: String = return_file("/home/swq/playground/rust_book/result/src/hello.txt").unwrap();
println!("{}", _name);
}
10. Generic Types, Traits, and Lifetimes
10.1 Generic Data Types
The counterpart in C++ is template. C++ template and Rust generic are basically the same thing, with some differences.
The similarities are:
- Both support function, struct(class), method
- Both support specialization
- Both are static, meaning that they are resolved by compiler at compiling time, no runtime overhead
Some differences are very subtle, we will use examples to demonstrate. The main differences are:
- Rust support enum generic, while in C++ there are no enum template
- Since Rust has more powerful enum with associate value
- Rust has more powerful type deduction ability:
struct MyStruct<T, U> {
a: T,
_b: U,
}
fn main() {
// we do not need to explicitly specify generic types here
let m = MyStruct { a: 1, _b: 3.14 };
println!("{}", m.a);
}
While in C++, programmer must explicitly specify type:
template <typename T, typename U> struct MyStruct {
T a;
U b;
};
int main() {
// Use of class template 'MyStruct' requires template
// argumentsclang(template_missing_args)
// C++ requires to specify template argument type
// MyStruct m = {.a = 1, .b = 4};
// ok
MyStruct<int, double> h = {.a = 1, .b = 3.14};
}
- Rust has more strict implementation check than C++. This means Rust might find errors in template itself, while C++ can only find errors when instantiation, for example:
#include <iostream>
template <typename T, typename U> class MyStruct {
public:
T a;
U b;
MyStruct(const T &_a, const U &_b) {
a = _a;
b = _b;
}
// c++ compile do not check whether T and U can be compared during template
// declaration; only checks when this template is instantiated
bool compare() { return a < b; }
};
struct SomeType {
double a;
};
int main() {
MyStruct<int, int> m = MyStruct<int, int>(1, 2);
std::cout << m.compare() << std::endl;
// if we do not have following instantiation, the code compiles OK, because
// implementation check happens when template is instantiated
SomeType s;
MyStruct<int, SomeType> t = MyStruct<int, SomeType>(1, s);
std::cout << t.compare() << std::endl;
}
But for Rust, it checks at generic definition time instead of generic instantiation time, which makes the error detection more earlier than in C++:
struct MyStruct<T> {
a: T,
}
// Rust checks whether T supports < operation at generic implementation time instead of instantiation time
// this means that errors in generics can be detect more earlier
// following code does not compile because rust have to know whether T support < or not at this time
impl<T> MyStruct<T> {
fn compare(&self, from: &MyStruct<T>) -> bool {
self.a < from.a
}
}
fn main() {
let m = MyStruct { a: 1 };
let n = MyStruct { a: 2 };
println!("{}", m.compare(&n));
}
To correct the code, we have to tell Rust compiler that the template argument supports all operations inside implementation:
// tells Rust that T can be compared with each other
struct MyStruct<T: std::cmp::PartialOrd> {
a: T,
}
impl<T: std::cmp::PartialOrd> MyStruct<T> {
fn compare(&self, from: &MyStruct<T>) -> bool {
self.a < from.a
}
}
fn main() {
let m = MyStruct { a: 1 };
let n = MyStruct { a: 2 };
println!("{}", m.compare(&n));
}
10.2 Traits: Defining Shared Behavior
There is no exact counterpart in C++ for traits in Rust. The most close one is pure virtual function. Traits in Rust can be compared with interface in Java.
- A trait in Rust defines a set of method signatures that shared by any type that implement this trait
- Method inside a trait are defaulted to
pub, since trait are meant to be called - Method inside trait can have default implementations
- Inside default implementations, one can call other methods that have no default implementation
- When overriding default implementations, inside the overriding method, the default implementation of the same method can no be called
- One can implement external trait on type inside local crate, or implement local trait one external types, or implement local trait on local types:
- At least trait or type one of them must be local to current crate
- Otherwise, there might be duplicate implementations, since we do not know whether types in external packages implement the same trait on it or not. When this happens, Rust compiler do not know which trait implementation to use
- Using trait to restrict parameter types
// using impl
fn notify(para: &impl Summary) {
println!("{}", para.summarize());
}
// more general way
fn general_notify<T: Summary>(para: &T) {
println!("{}", para.summarize());
}
// para1 and para2 might have same or different types
fn multi_notify_impl(para1: &impl Summary, para2: &impl Summary) {
println!("{}\n{}", para1.summarize(), para2.summarize());
}
// the same as above
fn multi_notify_two<T: Summary, U: Summary>(para1: &T, para2: &U) {
println!("{}{}", para1.summarize(), para2.summarize());
}
// if we want restrict two parameters to same type, we have to use this way
fn multi_notify<T: Summary>(para1: &T, para2: &T) {
println!("{}\n{}", para1.summarize(), para2.summarize());
}
// using + operator
fn multi_notify_three<T: Summary, U: Summary + Display>(para1: &T, para2: &U) {
println!("{}{}", para1.summarize(), para2.summarize());
}
fn multi_notify_four(para1: &impl Summary, para2: &(impl Summary + Display)) {
println!("{}\n{}", para1.summarize(), para2.summarize());
}
// using where
fn multi_notify_five<T, U>(para1: &T, para2: &U)
where
T: Summary,
U: Summary + Display,
{
println!("{}{}", para1.summarize(), para2.summarize());
}
- Return types that implement trait
- Can not return different types in implementation. Compared with C++ virtual base class, trait here is static future, meaning that it is not achieved at runtime; While C++ virtual class is implemented at runtime, by virtual tables
fn returns_summarizable(switch: bool) -> impl Summary {
// no ok, can not return two different types that implement Summary
if switch {
NewsArticle {..}
} else {
Tweet {..}
}
}
#include <iostream>
#include <string>
class Base {
public:
virtual void f(){};
};
class DerivedOne : public Base {
public:
void f() override { std::cout << "from DerivedOne" << std::endl; }
};
class DerivedTwo : public Base {
public:
void f() override { std::cout << "from DerivedTwo" << std::endl; }
};
// return pointer to Base, but we do not know which type at compile time
Base *some_func(bool flg) {
if (flg) {
DerivedOne *ret = new DerivedOne();
return ret;
} else {
DerivedTwo *ret = new DerivedTwo();
return ret;
}
}
int main() {
int a;
char b[100];
std::cin >> b;
a = std::stoi(b);
// this will call different functions depending on user's input during runtime
some_func(a > 0)->f();
}
10.3 Validating References with Lifetimes
There is no counterpart in C++. Facts about Rust lifetimes:
- Lifetimes are generics, it’s part of the definition, whether it is used on functions, methods, or types
- Lifetimes are only used on reference, and every reference have lifetimes
- Lifetimes can be used on: functions, methods, types, just like generics
- Lifetimes do not change the code logic, and have nothing to do with memory allocation and deallocation, it is just programmer’s way to tell compiler the relationship between different references, so compiler can check possible dangling references during compiling time
// in following function, when this funtion be called,
// the return value might be &str1 or &str2, it is decided during runtime
// by specifying the lifetime generic 'a, we tell compiler that
// the return value can not outlive the shortest lifetime of str1, str2
// based on this information, compiler will check for us statically the
// lifetimes of return value, str1, str2, if any violations, error will
// be issued
// 'a literally means that there must be some lifetime that is overlapped
// by str1 and str2, and the return value lives inside this lifetime
// if compiler can not find this lifetime during compile time, error
// will be generated
fn longest<'a>(str1: &'a str, str2: &'a str) -> &'a str {
if str1.len() > str2.len() {
str1
} else {
str2
}
}
// it's not possible to return str2, so no need to explicitly specify for str2
fn shortest<'a>(str1: &'a str, str2: &str) -> &'a str {
if str2.len() > 100 {
str1
} else {
str1
}
}
- Types that contain reference data elements also require lifetime specifier
// Some can not outlive name, otherwise there is dangling reference
struct Some<'a>{
name:&'a String
}
- Compiler assign every reference a lifetime at compiling time, if programmer does not explicitly specify one for it, and they are different lifetimes and do not have relationship between each other. When programmer explicitly specify a lifetime generic parameter, that means variables that have this lifetime must have some lifetime that all these variables must outlive. As for what is this lifetime, it is decided by compiler at check time
-
Sometimes programmer does not need to explicitly specify lifetimes, it is called elision.
- Only function and method lifetimes have elision, struct definitions do not have elision, programmer must always explicitly specify lifetimes for struct definitions
- Lifetimes on function or method parameters are called input lifetimes, and lifetimes on return values are called output lifetimes.
- Compiler does elision based on three rules:
- The first rule is that the compiler assigns a lifetime parameter to each parameter that’s a reference. They are different parameters
- The second rule is that, if there is exactly one input lifetime parameter, that lifetime is assigned to all output lifetime parameters:
fn foo<'a>(x: &'a i32) -> &'a i32 - The third rule is that, if there are multiple input lifetime parameters, but one of them is
&selfor&mut selfbecause this is a method, the lifetime ofselfis assigned to all output lifetime parameters.
11. Writing Automated Tests
11.1 How to Write Tests
There is no built-in test frameworks for C++. Rust somehow build one test framework like Gtest into it’s standard library.
fn adder(left: u32, right: u32) -> u32 {
left + right
}
struct Guess {
value: i32,
}
impl Guess {
fn new(value: i32) -> Guess {
if value > 200 {
panic!("value too big:{}", value);
} else if value < 1 {
panic!("value too small: {}", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_adder() {
assert_eq!(4, adder(1, 3));
}
#[test]
fn test_adder_two() {
assert!(4 == adder(1, 3));
}
#[test]
fn test_adder_three() {
assert_ne!(3, adder(1, 3));
}
#[test]
// should_panic to test panics
#[should_panic]
fn should_panic() {
Guess::new(201);
}
}
11.3 Test Organization
Rust standard library supports two kinds of tests: unit test and integration test.
Unit test
Unit test is used to test every function or method, it should be written inside the source file, with test attribute and a special module called tests
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}
Integration Test
Integration test is used to test crate library as a whole. It uses the to-be-tested library the same as how end user will use it.
- Only library crate have integration test, binary crate do not need integration test, since itself is a executable
The structure of integration test:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
- Every source file directly under tests is treated as a individual crate and is a integration test unit
- Note the common/mod.rs, it is shared by all the integration test under tests folder, it has to be structured inside common folder, otherwise itself is treated as integration test too
Then the integration test can be written as:
// bring to-be-test library into integration test crate
use adder;
//declare common module
mod common;
#[test]
fn it_adds_two() {
common::setup();
assert_eq!(4, adder::add_two(2));
}
13. Functional Language Features: Iterators and Closures
13.1 Closures: Anonymous Functions that Capture Their Environment
Rust’s closures are anonymous functions you can save in a variable or pass as arguments to other functions. This has two meaning:
- Closures can be called like functions
- Closures can be bind to variable, so that it obeys lifetime rules like variables
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
// here list is borrorwed mutablly by closure, Rust compiler infer this accoriding
// to the operations inside closure body; also programmer can use 'move' keyword
// to explicitly tell closure to take owner ship of captured variables
// every closure is actually a data structure under the hood, Rust compiler keeps
// all the addresses of the captured variables
// if any parameters, Rust compiler will infer their type when the closure's first usage
let mut borrows_mutably = || list.push(7);
// this will tell compiler to take ownership of list, rather than use mut reference, which
// is infered by the code in closure body
// let mut borrows_mutably = move || list.push(7);
// nok, since list is already mutablly borrowed, it can not be immutablly borrowed for now
// println!("After calling closure: {:?}", list);
borrows_mutably();
// ok, closure has gone out of scope, now list can be borrowed again
println!("After calling closure: {:?}", list);
}
- Closures capture the environment in three ways, like parameters in function:
- Take the ownership of the captured variables
- Borrow immutably the captured variables
- Borrow mutably the captured variables
- Do not capture any variables in environment
-
Closures are types that implement Fn traits. There are three kinds of traits:
FnOnceapplies to closures that can be called once. All closures implement at least this trait, because all closures can be called. A closure that moves captured values out of its body will only implementFnOnceand none of the otherFntraits, because it can only be called once.FnMutapplies to closures that don’t move captured values out of their body, but that might mutate the captured values. These closures can be called more than once.Fnapplies to closures that don’t move captured values out of their body and that don’t mutate captured values, as well as closures that capture nothing from their environment. These closures can be called more than once without mutating their environment, which is important in cases such as calling a closure multiple times concurrently.- Closures can implement both these traits
- These traits are additive, which means that when there is a situation that requires a FnOnce trait bound, one can pass closures that implement either of the trait; while if requires a FnMut closure, one can only pass FnMut or Fn closure.
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
// F must be a FnOnce closure, it can accept any closures
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}
13.2 Processing a Series of Items with Iterators
- All iterators implement a trait named
Iterator
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// methods with default implementations elided
}
- Note that
nextmethod is the basis for a serials of methods that compose theIteratortrait, which have default implementations - There are three kinds of way to iterator over a sequence:
iter(): return immutable reference iteratoriter_mut(): return mutable reference iteratorinto_inter(): return owned value iterator
fn main() {
let mut v = vec![1, 2, 3];
// immutable reference
let imu_it = v.iter();
// mutable reference; both iterator and variable need to be mutable
let mut mu_it=v.iter_mut();
// take ownership
let own_it = v.into_iter();
}
Consuming adaptors
#[test]
fn sum() {
let v = vec![1, 2, 3];
// note that it does not need to be mutable to let sum() use next method,
// since sum() will take owership of it: it works very like std::move in c++
let it = v.iter();
// now 'it' is consumed, it can not be used again
let to: i32 = it.sum();
assert_eq!(6, to);
}
Iterator adaptors
Iterator adaptors return a iterator that behaves different with the original iterator
#[test]
fn map() {
let mut v = vec![1, 2, 3, 4];
let it = v.iter().map(|x: &i32| x + 1);
// collect method assign to new variable res
let res: Vec<i32> = it.collect();
// true
assert_eq!(vec![2, 3, 4, 5], res);
// original value do not change
assert_eq!(v, vec![1, 2, 3, 4]);
// this will change v
// note that map take a FnMut closure,which means it can change the captured variables
let mu_it: Vec<i32> = v
.iter_mut()
.map(|x| {
*x = *x + 1;
*x
})
.collect();
assert_eq!(mu_it, vec![2, 3, 4, 5]);
assert_eq!(v, vec![2, 3, 4, 5]);
// this will change v
for ele in v.iter_mut() {
*ele += 2;
}
assert_eq!(v, vec![4, 5, 6, 7]);
}
14. More About Cargo and Crates.io
14.3 Cargo Workspaces
Cargo workspace group together related packages and build them into one target folder.
- Even though packages are grouped inside one workspace, they are independent packages, which means that their own dependencies need to be explicitly specified in their own Cargo.toml file and publishing to create.io is also independent with each other
- Since all packages inside one workspace share the same Cargo.lock file, all dependencies of all packages are synced. If packages depend on same external package, this can assure that they dependent on the same version
15. Smart Pointers
15.1 Using Box<T> to Point to Data on the Heap
*Box
- Allocate memory for instance of T in heap
- *Box
* type itself is known size(like pointer size returned by `new`)
Comparing following code:
struct MyStruct{
node: Box<MyStruct>
}
struct MyStruct {
MyStruct *node;
MyStruct() { node = new MyStruct(); }
~MyStruct() { delete node; }
};
or
struct MyStruct {
// compile, but has segmentation fault(c++14)
std::unique_ptr<MyStruct> b = std::make_unique<MyStruct>();
};
- Both Rust and C++ no NOT support use type of itself as data member, since this will obviously compose infinite loop
- However, containing member that is type of itself is not the only way to come up with an infinite loop. Consider above code, both Rust and C++ code is infinite loop:
- Even though both code does not contain member that is the type of itself, they contain a ref to instance that is the type of itself. This will cause infinite memory allocation in the heap, in other words this is just infinite loop in heap instead of stack
- To break infinite loop, two conditions have to be met:
- Type must not contain members that is the type of itself
- There must be a break point for chaining of member containing
- The crux here is break of the recursive chaining
- To handle this, Rust and C++ takes different approach:
- Since Rust do not support default construction , user can not write code to create instance of MyStruct, because of the recursive nature of the type. Rust prevent this kind of mistake even before compile
- C++ compiler is not that responsible for your problem. The C++ code compiles and will segmentation fault at runtime since inside the constructor, the memory allocation is done recursively.
- To break the recursive chaining, Rust and C++ also takes different approach:
- C++ use
nullptr,unique_ptrto break the chain - Rust use
Option,Enumto break the chain
- C++ use
struct MyStruct {
node: Option<Box<MyStruct>>,
}
fn main() {
let r = MyStruct {
node: Some(Box::new(MyStruct { node: None })),
};
println!("This compiles");
}
or
struct MyStruct {
node: Box<Option<MyStruct>>,
}
fn main() {
let r = MyStruct {
node: Box::new(Some(MyStruct {
node: Box::new(None),
})),
};
println!("THIS ALSO COMPILES");
}
#include <iostream>
#include <memory>
struct MyStruct {
std::unique_ptr<MyStruct> b;
};
int main() {
auto a = MyStruct();
a.b = std::make_unique<MyStruct>();
if (a.b.get()) {
std::cout << "a contains b" << std::endl;
}
}
From above discussion, we can see that std::unique_ptr is comparable with Option<Box<T>> in Rust.
One more thing, following code does not compile either:
//recursive type `MyStruct` has infinite size
struct MyStruct {
node: Option<MyStruct>,
}
Even type does not contain member that is of type itself and recursive chain can be broken by None of Option . This is because Rust calculate the memory size based on the largest possible member.
15.2 Treating Smart Pointers Like Regular References with the Deref Trait
Deref coercion converts a reference to a type that implements the
Dereftrait into a reference to another type. For example, deref coercion can convert&Stringto&strbecauseStringimplements theDereftrait such that it returns&str. Deref coercion is a convenience Rust performs on arguments to functions and methods, and works only on types that implement theDereftrait. It happens automatically when we pass a reference to a particular type’s value as an argument to a function or method that doesn’t match the parameter type in the function or method definition. A sequence of calls to thederefmethod converts the type we provided into the type the parameter needs.
Mechanism with mut:
- From
&Tto&UwhenT: Deref<Target=U> - From
&mut Tto&mut UwhenT: DerefMut<Target=U> - From
&mut Tto&UwhenT: Deref<Target=U>
15.3 Running Code on Cleanup with the Drop Trait
Drop is comparable with destructor in C++.
- Unlike C++, in Rust programmer does not need to manually free memories, Rust compiler will do this for us. When a value is going out of scope, Rust will insert memory management code automatically.
- drop function inside Drop trait works very much like destructor in C++
- It is called automatically when value goes out of scope
- It can not be called manually, because there will be a double free problem just like C++
- Rust prevent this at compile time
- C++ throws at runtime
Unlike in C++, Rust’s drop can be called with std::mem::drop:
use std::mem::drop;
struct DropExample {
data: String,
}
impl Drop for DropExample {
fn drop(&mut self) {
println!("{} is being dropped", self.data);
}
}
fn main() {
let a = DropExample {
data: String::from("hello"),
};
let b = DropExample {
data: String::from("nihao"),
};
// drop function take ownership of b and b goes out of scope when drop returns
drop(b);
println!("Now let's drop:");
}
15.4 [Rc<T>, the Reference Counted Smart Pointer](https://doc.rust-lang.org/book/ch15-04-rc.html#rct-the-reference-counted-smart-pointer)
*Rc
- *Rc
* is only for use in single-threaded cases - Only immutable reference can be used inside *Rc
*
15.5 [RefCell<T> and the Interior Mutability Pattern](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#refcellt-and-the-interior-mutability-pattern)
*RefCell
- Like *Ref
* , it can only used on single thread situations. It only moves borrow check from compile time to runtime
Comparison of *Ref
- *Box
* is just a way to store data on the heap, except that it behaves much like any other variables. It can be borrowed immutably and mutably and Rust compiler will do borrow check at compile time - *Ref
* is single threaded, multi-owner, compile time checked, immutable reference container - *Ref
* stores value T in heap
- *Ref
- *RefCell
* is single threaded, single-owner, runtime checked, mutable and immutable reference container - *RefCell
* and *T* inside are stored together, there is no indirections involved, which is very different from *Box * and *Ref *
- *RefCell
- Both these three types owns the contained value
16. Fearless Concurrency
16.1 Using Threads to Run Code Simultaneously
Rust use closure to start a thread:
- If the closure need to catch variables in the environment, it must take ownership of it
use std::thread;
use std::time::Duration;
fn main() {
let v = vec![1, 2, 3];
// have to use move to take ownership of v
let handle = std::thread::spawn(move || {
println!("{:?}", v);
});
handle.join().unwrap();
}
- In this example, from the code we can see that the v outlives the thread because of the join.. part. However, Rust compiler still does not compile if we remove the move keyword. It says that if the new thread only use reference, it can not be certain that v will outlive the new thread(even it does in this example). This is very important because this limitation makes foreign API calling without worries of data race:
fn process_ve<T>(_:&mut Vec<T>){}
fn main() {
let mut v=vec![1,2,3,4];
// here we farelessly call api with worries about data race
// to v, since we know that if there is new thread inside
// this api, v can not be passed into it, for the owership
// can not be taken by the new thread
process_ve(&mut v);
let s=v.get(1);
if let Some(v) = s{
println!("{}", v);
}
}
16.2 Using Message Passing to Transfer Data Between Threads
Compared to C++, there is big difference between sharing data between threads:
- C++ communicates by sharing data
- Rust sharing data by communication
Rust use channel, which very much like pipe in Linux to send and rec between threads.
- channel can have multi senders, but only one receiver
- When sender sends data, it takes the ownership of the data
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
// val ownership is taken, can not be borrowed anymore
// println!("val is {}", val);
});
let received = rx.recv().unwrap();
println!("Got: {}", received);
}
16.3 Shared-State Concurrency
Introducing two more smart pointers for concurrent programming:
Arc<T>: it is the counter part ofRc<T>, the difference lies in thatArc<T>allow atomic updating of the reference counter, making it usable in multi-threading situationsRc<T>exist because in single thread situations, it has less overhead thanArc<T>
Mutex<T>: it is the counter part ofRefCell<T>, the difference lies in thatMutex<T>requires obtaining lock before borrow the value inside, making it suitable for multi thread situations.Mutex<T>has interior mutability likeRefCell<T>
use std::sync::Arc;
use std::sync::Mutex;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = std::thread::spawn(move || {
let mut m = counter.lock().unwrap();
*m += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("{:?}", counter.lock().unwrap());
}
17. Object-Oriented Programming Features of Rust
17.2 Using Trait Objects That Allow for Values of Different Types
Trait object in Rust can be compared with virtual base class in C++. There underlying mechanism is the same:
- Both use a pointer to object + a vtable that contain method indirection to achieve runtime polymorphism
Runtime polymorphism and generics(or template in C++)
- generic and template are statically dispatched at compile time(static dispatch), which means that their specific type is determined by the compiler at compiling time. They are instantiated during compilation
- Runtime polymorphism is dynamically dispatched at runtime(dynamic dispatch), which means that, at compile time, the compiler only know the base type(C++), or trait(Rust), compiler does not know the exact type. So at compile time, compiler will only do base type or trait check. However, it is not enough to only have these information for the program to run. The compiler also need to construct a vtable, which is used to look up method of the base type and trait at runtime. Now the program knows a pointer to object and a vtable that is used to find method of the object, at runtime the program use these two information to call methods(For C++, vtable pointer is always the first member after the object pointer).
- Every derived type in C++ and every type that implement some trait can be statically cast by the compiler to the base type pointer in C++ or trait object (which is also pointer) in Rust, plus (or included by the type pointer, if the vtable can be got by offset of the type pointer) a vtable
Limitations of runtime polymorphism
Runtime polymorphism seems to make the language dynamic typed, but it is not true. Dynamic language like Python keeps all meta data of a type, such as member name, method name and corresponding address. And object members can be changed at runtime. Runtime polymorphism is just a trick of the static language, which only have limited functionality:
- Compiler will still check the base type(C++) or trait(Rust), statically
Implementation difference between C++ and Rust
Although the underlying mechanism is similar, C++ and Rust is different:
- C++ use virtual base class based on inheritance. At runtime the derived type is downcast to the base type, which means that the derived type contains a continuous memory that can be cast into a base type object. Besides, virtual base class can also have data members.
- Rust use trait, like Java’s interface. It can not have data members. It’s a more modern way to use interface instead of inheritance, it makes the relationship more concise, while inheritance often inherit data members that the derived type does not need.
use std::env;
trait Sound {
fn make_sound(&self);
}
trait Color {
fn is_white(&self);
}
struct Dog {
kind: String,
color: String,
}
impl Color for Dog {
fn is_white(&self) {
println!("i am of color {}", self.color);
}
}
impl Sound for Dog {
fn make_sound(&self) {
println!("wang wang!, i am {}", self.kind);
}
}
struct Cat {
kind: String,
}
impl Sound for Cat {
fn make_sound(&self) {
println!("meow meow, i am {}", self.kind)
}
}
fn main() {
let mut zoo: Vec<Box<dyn Sound>> = vec![];
// Dog or Cat is not known at compile time
for item in env::args() {
if item == "Dog" {
// at compile time compiler will check pushed type and cast it to Sound trait object type
zoo.push(Box::new(Dog {
kind: String::from("any"),
color: String::from("any"),
}))
} else if item == "Cat" {
zoo.push(Box::new(Cat {
kind: String::from("any"),
}))
}
}
for animal in zoo {
animal.make_sound();
}
}
#include <iostream>
#include <string>
class Base {
public:
virtual void f(){};
};
class AnotherBase {
public:
virtual void g() = 0;
};
class DerivedOne : public AnotherBase, public Base {
public:
void g() override { std::cout << "from another base" << std::endl; }
void f() override { std::cout << "from DerivedOne" << std::endl; }
};
class DerivedTwo : public Base {
public:
void f() override { std::cout << "from DerivedTwo" << std::endl; }
};
// return pointer to Base, but we do not know which type at compile time
Base *some_func(bool flg) {
if (flg) {
DerivedOne *ret = new DerivedOne();
// when return, compiler will generate code that donwcast Drived type to
// Base, this makes all the differences
return ret;
} else {
DerivedTwo *ret = new DerivedTwo();
return ret;
}
}
int main() {
int a;
char b[100];
std::cin >> b;
a = std::stoi(b);
// this will call different functions depending on user's input during runtime
some_func(a > 0)->f();
}
19. Advanced Features
19.2 Unsafe Rust
Dereferencing raw pointers
Two kinds of raw pointers:
*const T:pointer to const variable, likeconst T*in C++*mut T: pointer to mutable variable, likeT*in C++
- Are allowed to ignore the borrowing rules by having both immutable and mutable pointers or multiple mutable pointers to the same location
- Aren’t guaranteed to point to valid memory
- Are allowed to be null
- Don’t implement any automatic cleanup
fn main() {
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
unsafe {
println!("r1 is {}", *r1);
println!("r2 is {}", *r2);
}
}
Calling unsafe functions or methods
unsafe fn dangerous() {}
unsafe {
dangerous();
}
- There can be unsafe blocks inside normal function or method!! The unsafe code does not make the whole function method unsafe
- External functions from other languages are all unsafe, since they are not checked by Rust compiler
extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}
Accessing mutable global variables
In Rust, global variables are called static variables:
- They have fixed memory address(unlike const, which might be duplicated when necessary)
- They can be mutable or immutable
- When they are mutable, accessing them is unsafe
static mut COUNTER: i32 = 0;
fn incre() {
unsafe {
COUNTER += 1;
}
}
fn main() {
incre();
unsafe {
println!("counter is {}", COUNTER);
}
}
Implementing unsafe trait
If one of trait method contains code that the compiler can not verify, such as raw pointer, the trait need to be specified using unsafe:
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}
19.2 Advanced Traits
Associate types
Inside trait definition associate types can be specified; it is a type placeholder, when implement the trait, the final type of the type placeholder will be specified:
- It works like generic, but it can only be specified once, during implementation, while generic can specify many times during implementation(specification) , or instantiation
Default generic types
Trait can be generic. Generic can have default type. The generic in Rust is very flexible.
- Default type saves type annotation every time the trait is used, at the same time allow future type specialization
- Default type also allow future modification of the trait, with additional type parameters, without breaking previous implementation of the same trait
// trait itself is generic, with default type
trait Some<T = i32> {
fn f(&self, a: T);
}
// since generic type has default value, we can in the future extend type parameter
// with default value like following, without break previous implementation
// replace above Some with following Some, the code still compiles, even now
// we have another generic parameter U
// trait Some<T = i32, U = String> {
// fn f(&self, a: T) {}
// }
// fn inside trait is generic
trait AnotherTrait {
fn g<T>(&self);
}
struct SampleStruct<T> {
data: T,
}
struct AnotherStruct<T> {
data: T,
}
struct ThirdStruct {}
struct FourthStruct {}
// Some here is template implemetnation
impl<T, U> Some<U> for SampleStruct<T> {
fn f(&self, u: U) {}
}
// conbine two types into one, trait and AnotherStruct must have same type
impl<T> Some<T> for AnotherStruct<T> {
fn f(&self, a: T) {}
}
impl<T> AnotherTrait for SampleStruct<T> {
// here the we can not use T as placeholder, because it have been used for SampleStruct
// the reason is that the generic is method type, when the method is called
// it can have unique parameter type than SampleStruct
fn g<U>(&self) {}
}
// use Some's defautl type i32
impl Some for ThirdStruct {
fn f(&self, a: i32) {}
}
// specialization for Some
impl Some<String> for FourthStruct {
fn f(&self, a: String) {}
}
fn main() {
let s = SampleStruct {
data: String::from("Hello"),
};
// can accept different types
s.f(23);
s.f(String::from("Hello"));
let a = AnotherStruct {
data: String::from("Hello"),
};
// a.f(23);
// can only be String, since AnotherStrcut and Some must have same type
a.f(String::from("helo"));
// type for g have nothing to do with SampleStruct
s.g::<i32>();
}
Fully Qualified Syntax
Rust allow same named methods and functions inside one type, to distinguish which methods to call, fully qualified syntax must be used:
*
struct Human;
impl Human {
pub fn introduce(&self) {
println!("I am human")
}
}
trait Teacher {
fn introduce(&self);
}
trait Polic {
fn introduce(&self);
}
impl Teacher for Human {
fn introduce(&self) {
println!("I am teacher")
}
}
impl Polic for Human {
fn introduce(&self) {
println!("I am polic")
}
}
fn main() {
let human = Human;
// calling introduce of Human
human.introduce();
Human::introduce(&human);
// calling Teacher::introduce
<Human as Teacher>::introduce(&human);
// calling Polic::introduce
<Human as Polic>::introduce(&human);
}
Supertrait
When implement one trait for a type, we can require that the type must also implement other traits. The trait we are implementing now depend on other traits.
use std::fmt;
// types that implement OutlinePrint must also implement Display
trait OutlinePrint: fmt::Display {
fn outline_print(&self);
}
19.3 Advanced Types
Newtype
A newtype is a type wrapped inside a tuple struct, this type will be treated by compiler as a new type. It can be used when:
- Wrap an external type so we can implement external trait on this wrapper
- Wrap an regular type so we can give a special meaning to this type
Note that newtype is a real type, not the same as type alias, which is just syntax sugar and not treated by compiler as real type.
Type alias
Type alias can be compared with using statement in C++. It is used for a better code style. Compiler will replace the real type during compilation.
! never return type
! type is a special type that can be coerced into any other type
Dynamically Sized Types and the Sized Trait
Dynamically sized types are types whose memory occupation is not known at compiling time. This characteristic determines that we have to to pointer to refer to those types.
For example, str in Rust is dynamically sized type, we can not create str types directly, since we do not know how many memory this variable will take. However we can use &str type to point to str type, &str type is actually fixed sized, it stores address of the str and the length of the character. Similarly, Box<str> or Rc<str> is also correct since they are also pointers under the hood.
- Every trait is a dynamically sized type we can refer to by using the name of the trait. Trait objects are all dynamically sized types
- Rust provides the
Sizedtrait to determine whether or not a type’s size is known at compile time. This trait is automatically implemented for everything whose size is known at compile time. - Rust implicitly adds a bound on
Sizedto every generic function. Which means generic functions by default can only accept fixed sized type as parameters. To work with dynamically sized types for generic functions, it has to be explicitly specified:
// note the return type has to be a pointer like type
fn generic<T: ?Sized>(t: &T) {
// --snip--
}
19.4 Advanced Functions and Closures
Function pointer
fn is the function pointer type. Comparison with closure:
- closures in Rust can be seen as anonymous function type(like closures in C++)
fncan be seen as named function type(likestd::functionin C++)- Whether anonymous or named, they both can be seen as type
- closures can catch environment variables, while
fncan not - Since closures can capture variables, so according to the capture manner: mutable borrow, immutable borrow, take, there are three trait that Rust compiler will implicitly implement for every closure:
FnOnce,FnMut,Fn, these traits are used to describe the capture manners. fnimplement all three traits:FnOnce,FnMut,Fnbecause function pointers do not capture environment variables, so it will not influence it’s environment and can be called as may times. So anywhere a closure is capable, a function pointer with the same signature can also be used.- Both closure and function pointer have signatures, but there some differences:
- programmer does not need to annotate types when creating closure, since the types can be inferred from the user of the closure
fnmust annotate the type for the signatures becausefnare supposed to be used in anywhere- In simple words: closures are first defined by the user and then implemented when used;
fnare first defined and implemented, and then called by user of the function.
Returning closure
Since closures are anonymous, they can not be returned. But since closures implement trait and closures can be treated as trait object, so closures can be returned like this:
// define the closure
fn return_closure() -> Box<dyn Fn(i32) -> i32> {
// implement closure, no type annotation is requred, can be
// inferred from Box<dyn Fn(i32)->i32>
Box::new(|x| x + 1)
}
fn main() {
let a = return_closure();
let b = a(2);
println!("{}", b);
}