ara::com API: Part II — Proxy and Events
标准连接:ara::com API
NOTE
用词说明:
- 通信协议,驱动协议: 如果不是特别说明,这里通信协议指的是ComAPI底层使用的通信驱动协议,例如DDS、SOME/IP。注意不是网络协议
- ComAPI, ComAPI绑定,绑定层,绑定,适配层:这些都是指ComAPI层的接口实现,也称作绑定实现;它是存在于应用层与通信协议之间的适配代码
- Proxy,Proxy类,客户端:如无特别说明,都是指服务的消费方,Proxy接收Skeleton提供的服务
- Skeleton,Skeleton类,服务端:如无特别说明,都是指服务提供方,Skeleton为Proxy提供服务
- 服务实例,Skeleton类实例,Skeleton实例:都是指一个具体的服务实例, 它是Skeleton类的实例;服务实例全局唯一
- 消费实例,Proxy类实例, Proxy实例:是指一个具体的消费方,它有唯一的Client ID; 注意Proxy实例是没有服务实例ID的,服务ID是Skeleton实例的唯一标识符
- Skeleton/Proxy的实例与Seleton/Proxy类是两个概念,文中如果指的是实例,则会具体写明,否则指的是Skeleton/Proxy类本身
- 5 Detailed API description
5 Detailed API description
5.3 Proxy Class
The Proxy class is generated from the SI description of the AUTOSAR meta model. ara::com does standardize the interface of the generated Proxy class.
The toolchain of an AP product vendor will generate a Proxy implementation class exactly implementing this interface.
NOTE
Proxy的API接口是AUTOSAR定义好的,所有的代码引擎都需要生成符合标准要求的API
5.3.3 Constructor and Handle Concept
As you can see in the Listing 5.2 ara::com prescribes the Proxy class to provide a constructor. This means, that the developer is responsible for creating a proxy instance to communicate with a possibly remote service.
NOTE
Proxy类的特点可以总结如下:
static方法用于发现Skeleton实例- 应用开发者需要通过发现的
HandleType创建Proxy类的实例 - 一个Proxy类实例只能与一个Skeleton类实例通信
5.3.4 Finding Services
通过使用StartFindService和FindService两个static方法来发现Skeleton实例:
- StartFindService为异步发现,注册一个回调到ComAPI,每当有新的Skeleton实例被发现,回调会被调用
- FindService为同步发现,直接返回发现结果
这两个API都有两个重载,分别接收 ara::com::InstanceIdentifier和 ara::core::InstanceSpecifier,关于这二者的区别详见Part 1
5.3.4.1 Auto Update Proxy instance
当已经被发现的Skeleton实例由于各种原因暂停提供服务,而后又重新提供服务后,可以通过自动更新Proxy实例来继续通信,而无需重新走一遍FindService,创建Proxy实例的流程。
此外,允许在StartFindService注册的回调函数中直接使用已经存在的Proxy实例:
- 必须在调用这个回调前,做完自动Proxy实例的更新,这样才能保证Proxy实例的可用性
以上自动更新是通过底层的服务发现模块提供的状态来完成的.
NOTE
笔者对这个功能持保留意见:
- 为什么会允许出现在运行时Proxy实例更新的情况?按照文中所说,Proxy实例甚至允许出现底层传输层地址改变的情况,这严重违反了AUTOSAR部署的意义:既然已经是部署,就不能允许在运行时更新部署配置信息
- 即便在调用StartFindService注册的回调前自动更新了已经存在的Proxy实例,那也不能保证在调用这个实例的API时对方的Skeleton实例仍然有效。因为这中间存在时间差,而对方Skeleton实例可能远在另外一台机器。
5.3.5 Events
5.3.5.1 Event Subscription and Local Cache
如果Proxy实例端想要接收Skeleton实例中的一个event,则必须使用event订阅这个接口。这个接口有两个作用:
- 告诉ComAPI需要接收这个event的数据
- 告诉ComAPI需要在ComAPI层开辟多少存储空间用于存放数据
NOTE
ara::core::Result<void> Subscribe(size_t maxSampleCount); :
maxSampleCount表示当前Proxy需要为当前event开辟的存放缓存数据的池子大小,这个池子与底层的协议绑定完全无关,比如DDS和SOME/IP,它不是底层协议的缓存,而是ComAPI binding层的缓存- 在
GetNewSamples接口中需要将底层通信协议,例如DDS和SOME/IP,中的数据直接解序列化到这个池子,然后将指向这个池子中数据的指针SamplePtr传给上层应用;SamplePtr的行为将在后续小结详细说明
5.3.5.3 Accessing Event Data — aka Samples
So there has to be taken an explicit action, to get/fetch those event samples from those buffers,eventually deserialze it and and then put them into the event wrapper class instance specific cache in form of a correct SampleType. The API to trigger this action is
GetNewSamples().
NOTE
- 从绑定协议的底层,例如DDS的history,中获取未序列化的数据流。注意这些数据流可能存储在底层绑定协议的缓存中,也可能在内核空间中,例如在IPC socket、shared memory中。这些数据通常是从本地IPC,例如unix domain socket,或者UDP/TCP socket中获取的原始数据包,尚未完成反序列化。
- 将原始字节流反序列化,然后存储在ComAPI的本地缓存中,即上面所说的
local cache中,其大小在Subscribe(size_t maxSampleCount)时,由应用告诉ComAPI; 注意,为了保证运行时的确定性,这个池子的内存应当是固定的,不能在运行时重新申请、释放。另外,为了减少Copy,根据底层绑定协议的能力,应当尽量直接将数据反序列化到池子中,而不是先反序列化,然后Copy。
On a call to GetNewSamples(), the ara::com implementation checks first, whether the number of event samples held by the application already exceeds the maximum number, which it had committed in the previous call to Subscribe(). If so, an ara::Core::ErrorCode is returned. Otherwise ara::com implementation checks, whether underlying buffers contain a new event sample and — if it’s the case — deserializes it into a sample slot and then calls the application provided f with a SamplePtr pointing to this new event sample. This processing (checking for further samples in the buffer and calling back the application provided callback f) is repeated until either:
- there aren’t any new samples in the buffers
- there are further samples in the buffers, but the application provided maxNumberOfSamples argument in call to GetNewSamples() has been reached.
- there are further samples in the buffers, but the application already exceeds its maxSampleCount, which it had committed in Subscribe().
NOTE
GetNewSamples接口的行为:
template <typename F>
ara::core::Result<size_t> GetNewSamples(
F&& f,
size_t maxNumberOfSamples = std::numeric_limits<size_t>::max());
maxNumberOfSamples:GetNewSamples接口传入的本次希望接收的最大数据数量maxSampleCount:local cache本地缓存的池子大小;大小由Subscribe(size_t maxSampleCount)时,由上层应用指定- 底层绑定协议中buffer区域的可用的未读取的数据数量,姑且称为
bufferUnreadCount
GetNewSamples从底层通信获取未读的、未序列化的消息,将其序列化,存储到local cache池子中,然后将指向这个数据的SamplePtr指针作为参数传递给回调函数f. F必须是void(ara::com::SamplePtr<SampleType const>).类型。这个过程一直循环,直到:
- 所有
bufferUnreadCount消息全部处理完 - 或者,
local cache的数量已达到maxSampleCount - 或者,本次已读取
maxNumberOfSamples个数据
5.3.5.4 Event Sample Management via SamplePtrs
SamplePtr需要满足如下功能:
- 它指向的内存区域应当是ComAPI申请的,与底层绑定的协议无关,且会被重复利用的区域;这意味着这些内存区域不会频繁的释放和申请
- 它指向的应当是应用层可以直接使用的数据类型,及已经完成反序列化
- 它指向的数据的所有权必须可以从ComAPI层
move到应用层,且:- 如有必要,为了极致的性能优化,它还应当支持引用计数,即同时将所有权给不同的应用层的Proxy
- 当其所有权被应用层释放,应当通知到ComAPI实现层,这样ComAPI就可以将其指向的内存区域重新利用;这里可以有两种方式:
- 在
SamplePtr析构时,通过类似引用计数的方式将释放信息传递给ComAPI,这个机制可以参考std::shared_ptr - 在
SamplePtr中开放对应的API接口,应用程序使用完毕后,显式调用该接口释放内存
- 在
5.3.5.5 Event-Driven vs Polling-Based access
Proxy端event的polling和event-driven模式分别通过两个API实现:
- polling:
GetNewSamples实现polling - event-driven:
SetReceiveHandler(ara::com::EventReceiveHandlerhandler)注册一个回调,底层通信协议在收到新的消息后会调用这个回调- 在这个回调中再调用
GetNewSamples获取数据
- 在这个回调中再调用
5.3.5.6 Buffering Strategies
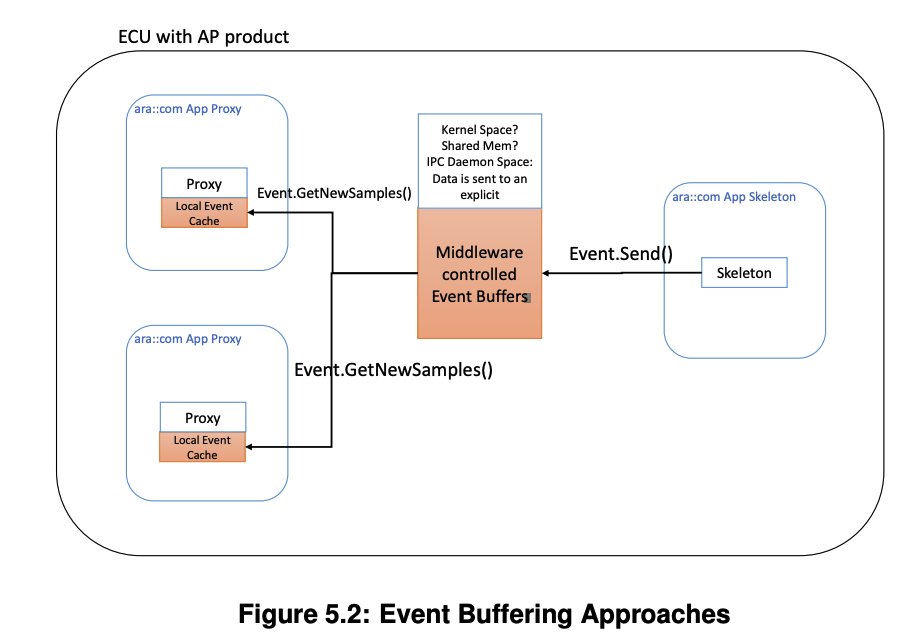
在讨论之前,必须设定一些前提,不然讨论起来情形非常多;主要有以下几方面的原因:
- 这个Skeleton实例可能在当前机器,当Skeleton实例发送数据时,可能会将数据保存在:
- kernel空间:例如unix domain socket,pipe
- shared memory
- daemon 进程:这是指专门用来分发的进程;当daemon进程与Proxy通信时也可以选择共享内存、unix domain socket、pipe等
- 这个Skeleton实例可能在另外一台机器,当其发送数据,可能会将数据保存在:
- kernel空间:例如TCP/UDP socket
- daemon进程:同上
- Proxy实例可能在同一个进程中,也可能在不同的进程中
- 如果Skeleton实例在当前机器,Skeleton实例和Proxy实例在同一个进程都是有可能的
Proxy实例和Skeleton实例不同的位置关系,使用的IPC技术方案,都会直接影响Proxy实例之间的数据共享。所以,我们限制如下:
- 不同的Proxy实例在不同的进程;做这个限制的原因是,同一个进程中收取两份相同的数据实际意义很小
- Skeleton实例在另外一台机器;做这个限制的原因是这种情况最终会转化为同一台机器的共享,因为数据必须先通过网络到达当前机器
如何实现不同Proxy实例之间的event数据共享:
- 首先需要一个Proxy实例所在机器的daemon进程统一管理与外部机器的网络数据收发,因为如果当前机器不同的Proxy实例分别与外部机器的Skeleton实例创建了网络连接,则会有重复的数据在网络发送;在Skeleton一侧,也应当有daemon进程,因为Proxy实例和Skeleton实例能相互通信的前提是底层使用了相同的通信协议(在模型中它们来自同一个部署),例如DDS或者SOME/IP
- 在服务发现阶段,也应当由daemon进程统一管理,只有这样这个daemon进程才能汇总、梳理可能共享event数据的Proxy实例,例如如果不同的Proxy实例都同时订阅了一个相同的Skeleton实例,则这两个Proxy实例可以共享event数据
- 在收到原始数据流后,daemon必须先对数据进行反序列化,才能共享;否则,如果共享的是为序列化的数据,则每次使用都必须反序列化,显然失去了共享的意义
- 在将数据反序列化后,daemon应当将数据保存在共享内存中,这样在不同地址空间中的Proxy实例才能通过指针的方式共享这些数据
- Proxy实例的
local cache中存储的不再是值,而是数据的指针;且daemon进程中必须使用引用计数的方式来管理这些共享数据 - 当Proxy实例将数据,即
SamplePtr给上层应用时,给的是指向daemon原始数据的指针;但是在这个SamplePtr的实现中,必须提供接口,或者在析构时,能够告知ComAPI层,当前local cache中的这个指针已经被应用层释放,从而ComAPI可以通知通信协议的daemon进程减少当前数据的引用计数 - 当daemon进程管理的数据引用计数为0时,可以释放该数据
缺点:
- 不同Proxy实例会同时影响daemon进程中的event数据缓存量:任何缓存都是有限制的,一旦超过了限制,则必须选择丢弃新的数据,或者阻塞发送端(例如TCP);如果不同Proxy实例之间对数据消耗的速度是不同的,则可能会出现相互影响:消费快的Proxy实例可能会因为消费慢的Proxy实例而牺牲掉获取数据的机会;相比较而言,如果每个Proxy实例都有自己的缓冲copy,则不会出现这个问题
- 不同的进程对数据的存储可能有不同的对齐要求,如果使用共享内存,则必须要考虑这个问题