Reference Counting in Systems
reference count is a recurring design pattern in many fields of computer systems. It’s interesting to put them together and have a look at them.
If not otherwise specified, all pictures used in this blog comes from the book: The Linux Programming Interface.
i-node reference count:hard links
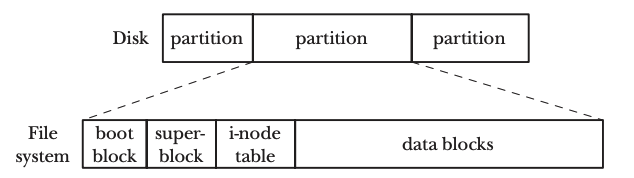
let’s first have a recall about how a file is stored in disk logically. we don’t go into details about how file is physically stored in disk, which is the job of the disk controller. From the point of the operating system, the disk is composed of continuous logical blocks. A disk might have been partitioned into several partitions, every partition can contain a individual file system. Following discussion is based on the ext2 file system.
 |
|---|
| The position of i-node |
The i-node table is the index of all the files that resides in this partition(aka, file system). i-node table contains i-node entry. An i-node entry defines a file inside the file system, here a file can be a regular file, a directory, a symbol link. The i-node entry contains basically all the meta information about the file: type of the file, creation time, access settings, logical block numbers that store the content of the file, etc. Note that the logical block numbers are continuous inside the i-node entry, but each logical block number can point to any logical block, which implies:
- even though the logical blocks are continuous from the perspective of the operating system, the file system stores each file discretely among all logical blocks
- logical blocks themselves are again allocated discretely among all physical blocks by the disk controller
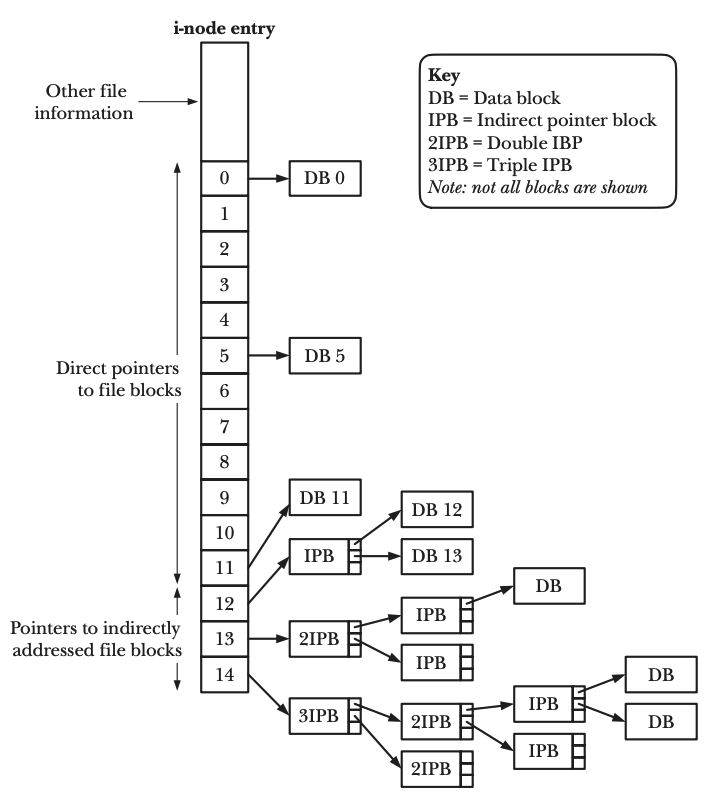
As the result of those two level indirections, a file can be concieved as being stored discretely in a disk. Before going into our main topic about the reference count, it’s worth to know about how an i-node entry is structured. No matter the size of a file, the i-node entry for the file has a fixed size. This, again, is achieved by indirection.
 |
|---|
| i-node internal structure |
Note that every pointer is to a logical block, and suppose that a logical block is 1024-bytes, a pointer is 4-bytes, there can be a lot of blocks referenced by a single i-node entry. That is why one i-node entry can contain information about very large files.
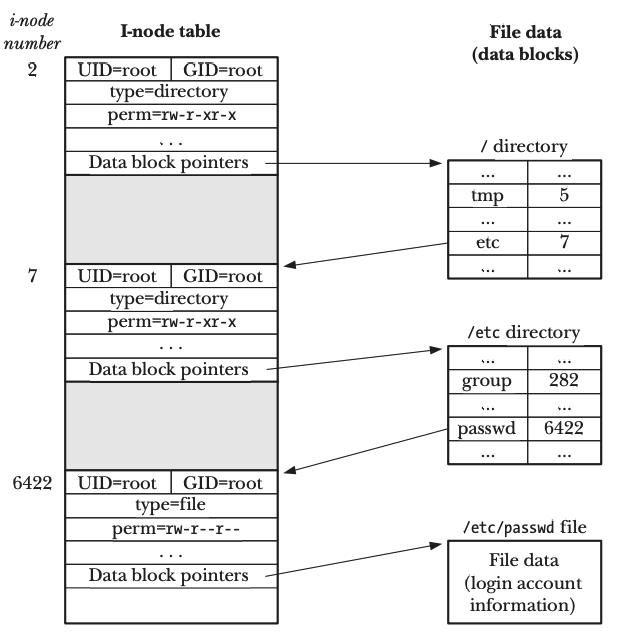
A folder, like a regular file, is also represented as an i-node entry inside i-node table. Folders also need logical blocks to stores it’s content, the difference between folders and regular files lies in the content. For a regular file, the content stored in logical blocks are user data; For folders, the content are key-value pairs that describe the files inside the folder. The key is a string representing the file name; The value is the i-node number of this file.
 |
|---|
| file path |
When we try to open a file, such as “/a/b/c”, we can imagine the following steps:
- ”/” folder i-node entry is iterated to look for the i-node corresponding to file name “a”
- iterate i-node found in step 1 to look for the i-node corresponding to file name “b”
- repeat above steps until file name “c” is found, together with the i-node number
- from the i-node number, retrieve the logical blocks numbers that are used to store file “c”, and read content from those logical blocks by interacting with disk controller
Finally we come to the point of our topic, the reference counting. It’s very intuitive to ask that what if two file names in two difference folders both point to the same i-node entry? An i-node can be referenced by multiple hard links. For example, “/a/b/c” and “/e/f/g” might both point to the same i-node. Linux syscall link(..) and unlink(..) are used to create and remove a hard link to a specific i-node entry. When new hard link is created, the reference count for the i-node is incremented. When hard link is removed for the i-node, the reference count is decremented. When the reference count is reached 0, the i-node entry and the logical blocks that are associated with this i-node are all freed by the file system(also require that all file descriptors that refer to this i-node are all closed).
open file description reference count
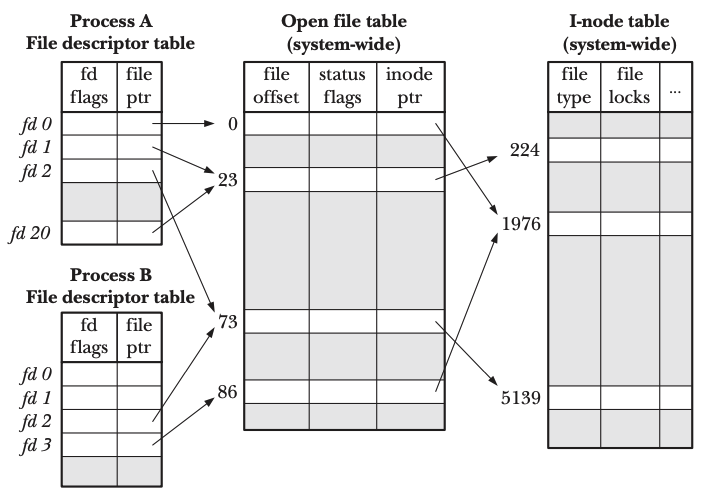
When a file is opened, the corresponding i-node is searched and loaded by the file system. There is one file description for this open action. If the same file is opened multiple times, there will be multiple file descriptions. If different hard links that link to the same i-node are opened, there are multiple file descriptions that point to the same i-node. The opened file description is system-wide, meaning that it might be shared by different file descriptors. Those descriptors might be in the same process, or they can be in different process. Different file descriptors refering to the same file description in the same process might be created with dup, dup2 system call; Different file descriptors refering to the same file description in different process might be created with fork system call. The same file description shares read/write offset and status, etc, because the file description is opened once.
 |
|---|
| file descriptor, file description and i-node relationship |
There is a reference count for every file description, one file descriptor adds one count into a file description. When all the file descriptors refering to the file description are closed, the file description is closed by the file system.
garbage collection and c++ smart pointers
Reference counting is also used by many other fields, amoung them are garbage collection for programming languages and c++ shared pointer design. In programming languages that support garbage collection, every variable created in program is counted by code that are automatically generated by the compiler, when one reference to this variable is going out of scope, the reference count is decremented. When the reference count is reduced to 0, the variable is collected as garbage, meaning that the memory occupied by this variable is returned to the kernel. The design of the c++ shared pointer is very similar to that of the garbage collector,except that the reference counting is implemented by programmer instead of the compiler.